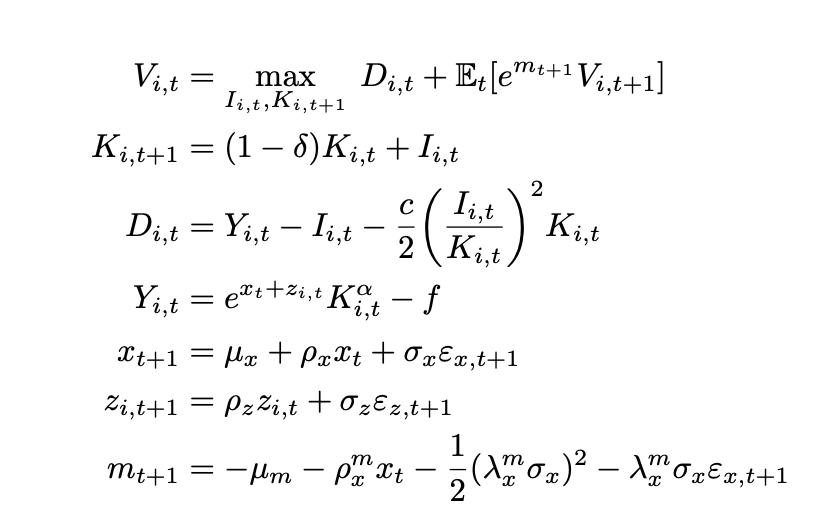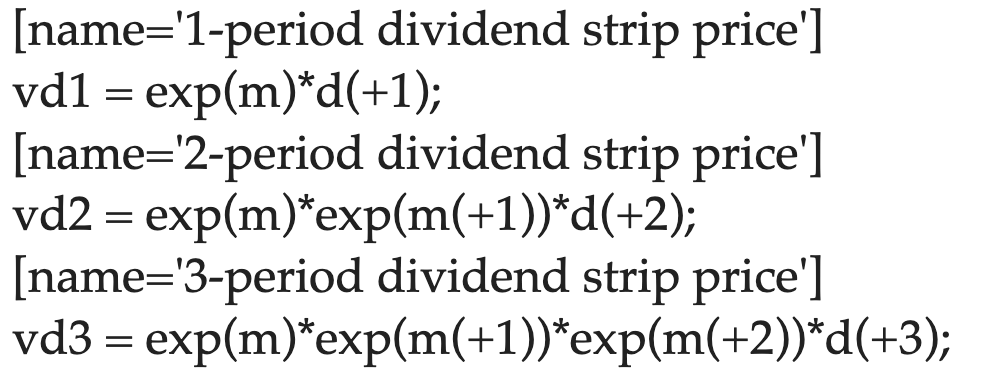Thank you so much for correcting my code and, in fact, rewriting a significant portion of it. I truly appreciate your help! I am able to run your file smoothly with Dynare 6.1.
I have some questions regarding the code and Dynare in general
-
Why do you declare level variables instead of log variables? As I read from Dynare tutorials, both are fine and legit. And log variables provide an easier interpretation of IRF, no?
-
What is the purpose of declaring var(log) y;? From what I read, y remains the level of output, not log output.
-
Could you explain this line for SDF? What does “#” at the beginning represents? I understand that, because you specify m is driven by ex(+1), accordingly, you use m instead of m(+1) in the FOC.
#m = -rf - 0.5*(lambda_mx * sigma_x)^2 - lambda_mx * sigma_x * ex(+1);
[name='FOC']
1 + theta * i/k = exp(m) * (alpha * y(+1)/k(+1) + 0.5 * theta * (i(+1)/k(+1))^2 + (1-delta) * (1+theta * i(+1)/k(+1)));
- How can I set seeds in the simulation
N_firms=5;
N_periods=500;
x_rand=randn(N_periods,1);
z_idio=randn(N_periods,N_firms);
log_y_pos=strmatch('LOG_y',M_.endo_names,'exact')
log_y_save=NaN(N_periods,N_firms);
for iter=1:N_firms
ex_=NaN(N_periods,M_.exo_nbr);
ex_(:,strmatch('ex',M_.exo_names,'exact'))=x_rand; %keep fixed
ex_(:,strmatch('ez',M_.exo_names,'exact'))=z_idio(:,iter); %iterate over firms
y_=simult_(M_,options_,oo_.dr.ys,oo_.dr,ex_,options_.order);
log_y_save(:,iter)=y_(log_y_pos,2:end);
end
- Could I interpret the specification of the timing as follows:
At the beginning of period t, exogenous shocks \varepsilon_{x,t} and \varepsilon_{z,t} are realized.
The firm yield output Y_t = e^{x_t + z_t}K_t^{\alpha}, where K_t is the capital stock also at the beginning of period t.
Upon observing these shocks, the firm chooses the level of investment to maximize its firm value V_t.
The firm maximizes the cum-dividend value of the firm V_t, which equals the sum of current dividend D_t and the expected discounted value of the continuation value \mathbb{E}_t[M_{t+1}V_{t+1}], where M_{t+1} is driven by the shock \varepsilon_{x,t+1} realized in the beginning of the next period t+1.
The resulting V_t is realized at the end of period t after the investment decision is made.
Although we distinguish the beginning/end of the period t, they are all just labelled by time t.
- Could I calculate the value and return of the firm as follows? (Assuming that I have declared those variables)
[name='cum-dividend value']
vc = d + exp(m) * v(+1);
[name='ex-dividend value']
ve = exp(m) * v(+1);
Subsequently, I can calculate returns in matlab as follows
r = vc(2:end) ./ ve(1:end-1);