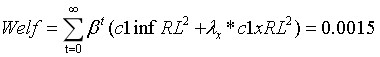Dear Johannes,
Sorry for the late reply. I really appreciate your help! Would you mind if I have few follow-up questions:
1, As you said, “ If you compute the FOCs yourself, you can include the recursive definition of the planner objective in the model-block.” and “there is a conflict between perfect foresight and using a welfare criterion derived based on variances”. I am not sure if I understand it correctly. From my understanding of your explanation, adding the recursive definition of welfare into the mode_block to obtain correct welfare is only possible when shocks are assumed to be stochastic and we use “stoch_simul” command to simulate the model stochastically. However, in the environment of perfect foresight, even adding the recursive definition of welfare in the model_block would lead to a zero value of welfare as the variances of inflation and output gap are generally zero. Am I right?
2, Now I have two mode files and both can replicate Jung, Teranishi and Watanabe (2005), which is essentially optimal commitment policy for the textbook NK model under ZLB and AR(1) perfect foresight demand shock.
Jung2005_Occbinding.mod (2.1 KB) let Dynare to compute the FOCs. I use the
“evaluate_planner_objective” function there. If we run it, Dynare reports the values of welfare:
Simulated value of unconditional welfare: 0.00000000
Simulated value of conditional welfare: 0.00146289
Jung2005.mod (2.4 KB) is also the code to replicate Jung, Teranishi and Watanabe (2005). But now I derive the FOCs manually and puts FOCs into Dynare directly. Also, as you suggested, I add the recursive definition of welfare: “Welf = (c1infRL^2 + lambda_x * c1xRL^2) + bettap * Welf(+1)”, where the period loss function is ”L_t = (c1infRL^2 + lambda_x * c1xRL^2)” with “c1infRL” being inflation and “c1xRL” being output gap. If we run Jung2005.mod (2.4 KB), it also reports the values of “Welf”, which consists of sequence of numbers (if we choose the first ten periods):
Welf = [ 0 0.0015 0.0006 0.0005 0.0003 0.0001 0.0000 0.0000 0.0000 0.0000 ]
My question is what might be the differences and links between the welfare reported from Jung2005_Occbinding.mod (2.1 KB) and the “Welf” generated from Jung2005.mod (2.4 KB).
3, A follow-up question is how does Dynare compute the welfare if we let Dynare compute the planner’s FOCs and apply the “evaluate_planner_objective-function” under perfect foresight shock, for example for Jung2005_Occbinding.mod (2.1 KB).
4, Would it be possible for you to talk more about “simulated ex-ante welfare”? What does that mean? How does it differ conceptually with the welfare number obtain from runningJung2005_Occbinding.mod (2.1 KB) or Jung2005.mod (2.4 KB)? How should we think about the difference between “simulated ex-ante welfare” under perfect foregisht shocks and the (conditional or unconditional) welfare we typically use under stochastic shocks? And how should we compute it in Dynare, or alternatively how to compute it for Jung2005.mod (2.4 KB)?
5, In case of stochastic shocks, we can use the conditional or unconditional welfare to evaluate the performance of different policies. My question is what is the proper or best measure of welfare in models with ZLB and perfect foresight shock?
Thanks a lot in advance!
Best regards
Andy