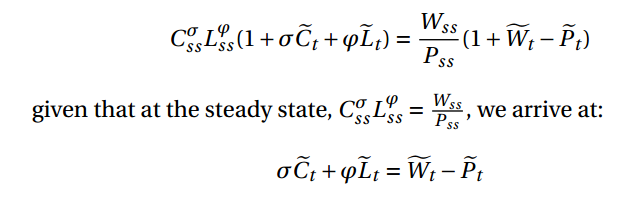I found the irfs from my non-linearized model (for which, I directly put into the model section, without exp(), nor loglinear option, and in this command::stoch_simul(order=1, periods=2000, irf=100) ), is different from the irfs from the hand log-linearized above model (for which, I put after the model (linear); command, and with the same: :stoch_simul(order=1, periods=2000, irf=100) )
is it possible that the irfs from the linearized and log-linearized not the same, or I made a mistake somewhere, these irfs should be the same.
P.s. there are variable whose steadystate value is 0. And I am not sure I do this correct, in log linearizing model, I use the following linearization for 0 steady-state variables:
If I understand your description correctly, you are comparing non-logged levels in the nonlinear model to the logged version in the linearized model. Those IRFs will obviously not be the same, because one is in percent, the other not.
I know their values of change (the values in the vertical axis in the irf graphs) are different (one is in percentage and the other is in levels) , but will the shape of the irfs the same, I tried the simple RBC model and found though their values are different, their shapes look the same.
Oh, thanks a lot for the reminding. I am not sure I understand you correct. I didn’t take logs for the equations first and then approximate the whole equations…
I log linearized by replacing the non-0-steady-state varaibles using the following approximation:
x_t = x_bar *(1+ x^hat_t)
or
x_t = x_bar * exp(x^hat_t)
where, x_t is the vairable, x_bar is the steady state of the variable, x^hat_t is the percentage deviation of x_t to x_bar.
I tested some equations, and found this approach produce the same result as taking logs of the equations first and then approximate the whole equations.
And becuase I cannot get percentage deviation for 0-steady-state variables, (x_t-0)/0 would be infinity, so, I just use level deviation for 0-steady-state variables, that
x_t = x^hat_t
while here, x^hat_t is the level deviation of x_t to x_bar, where x_bar =0.
not
x_t = x_bar *(1+ x^hat_t)
But I am not sure this inconsistance will cause difference in the irfs from linearized and log linearized equation.
Is this your own developed technique? I think you should not take logs first. Use a standard log-linearization technique like Uhlig’s. Example here. You don’t need to take logs first.
Thanks a lot for the clarification. Sorry for the confusion, I thought you mean take log first. Yes, I am using your approach for hand log linearization. But the irfs from my hand linearized model is different from the irfs from the non-linearized model. Not sure where goes wrong.
For taking logs, I saw Eric sims’s notes doing so. e.g:
There are different ways to log-linearize at first order, but they should all results in the same outcome. @Olivia If you are unsure how to do this, then you should not be linearizing by hand. It’s too error-prone. Let the compute do it. See also Why do we log linearize a model by hand?
Regarding steady state 0: in this case, you do not log-linearize, you linearize. Thus, the IRFs should be identical to the nonlinear version at first order.
Sorry to be repetitive, Just wanna double check with you,
For
Does it mean
if I use exp() for log linearization, I will not use exp() on 0-steady-state-value variables, but on other non-0-steady-state-value variables which I want to measure in percentage?
If I want to hand log linearize the whole model by hand, I will leave 0-steady-state-value variables as x_t itself or replace it by x^hat_t (in fact they are the same?), and not replace it by x_ss * exp(x^hat_t) as other non-0-steady-state-value variables do?
where x_t is the variable itself,
x_ss is the steady state of the variable,
and x^hat_t is the deviation from steady state for 0-steady-state-value variables, and percentage deviation from steady state for non-0-steady-state-value variables.