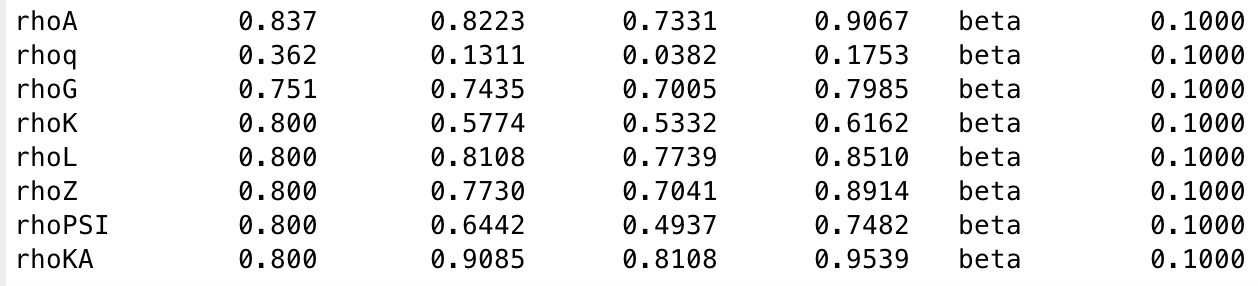
Hi all,
I am trying to compare environmental policy instruments in an NK model using the standard consumption-equivalent measure. I found the mod file for Born and Pfeifer (2018) and have been working to replicate it. I have attached my files below. I have two questions:
-
I try to define four different policy scenarios (baseline, tax, intensity, cap) using if conditions throughout the mod file. However, the code as it is only performs estimation on the ‘tax’ scenario. How should I specify multiple policy regimes within a single mod file, and where are the estimation results for each regime reflected in the output?
-
In BP (2018), natural output Y_nat and hours worked N_nat are explicitly defined. Therefore, ‘Recursive_natural_welfare_equivalent’ is specified as follows. It is consistent across policy regimes and the welfare differences are always calculated using reductions in the flex-price natural consumption. In my case, however, baseline consumption and labor are not separately defined. How would I reflect in the code that for each policy, (1-lamda_utility) should always be applied to the baseline consumption, rather than the ‘c’ that arises in each policy scenario?
[name=‘Natural Recursive Welfare’]
Recursive_natural_welfare_equivalent=Z*(log((1-lambda_utility)Y_nat)-N_nat^(1+varphi)/(1+varphi))+bettaRecursive_natural_welfare_equivalent(+1);
Thank you in advance.
Best,
Yang
cn_test_one_sided.xlsx (15.4 KB) cn_welfare.mod (12.9 KB) get_consumption_equivalent_conditional_welfare.m (2.4 KB) get_consumption_equivalent_unconditional_welfare.m (2.2 KB)