Hello, While implementing the “Bridging DSGE models and the raw data” paper by Fabio Canova (2014), I encountered unexpected behavior in shock_decomposition that I’d appreciate help understanding.
The Issue:
- My toy RBC model includes an AR(1) productivity process:
z(t) = rho_z * z(t-1) + eps_z(t),where z doesn’t depend on any other endogenous variables. I expected the “initial values” contribution in shock_decomposition to decay monotonically at rate rho_z^t. However, it fluctuates non-monotonically. - Furthermore, the smoothed z values don’t satisfy the AR(1) law: comparing oo_.SmoothedVariables.z(2:end) with rho_z*oo_.SmoothedVariables.z(1:end-1)+oo_.SmoothedShocks.eps_z(2:end) shows significant discrepancies.
- Finally, in initial_condition_decomposition, z’s own contribution decays as expected, but the aggregate “initial values” still fluctuates.
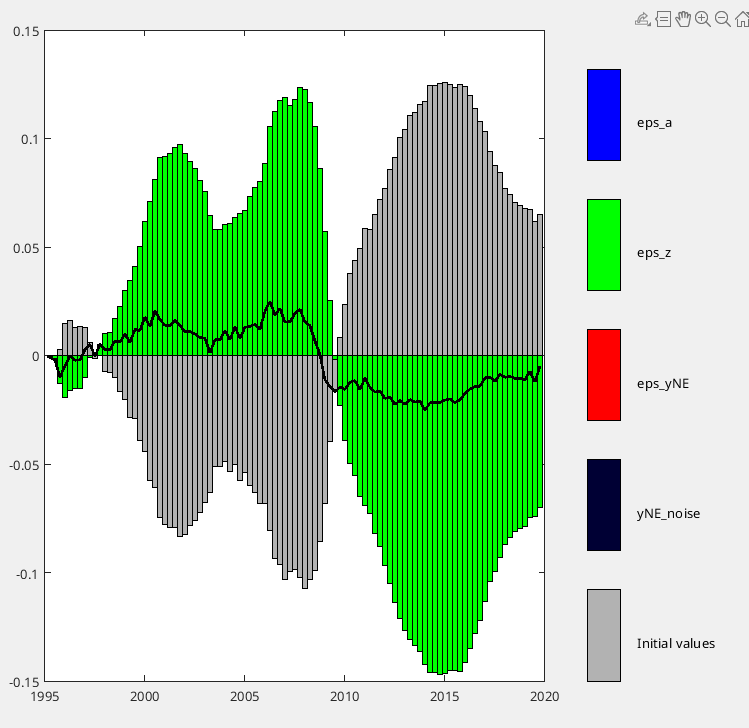
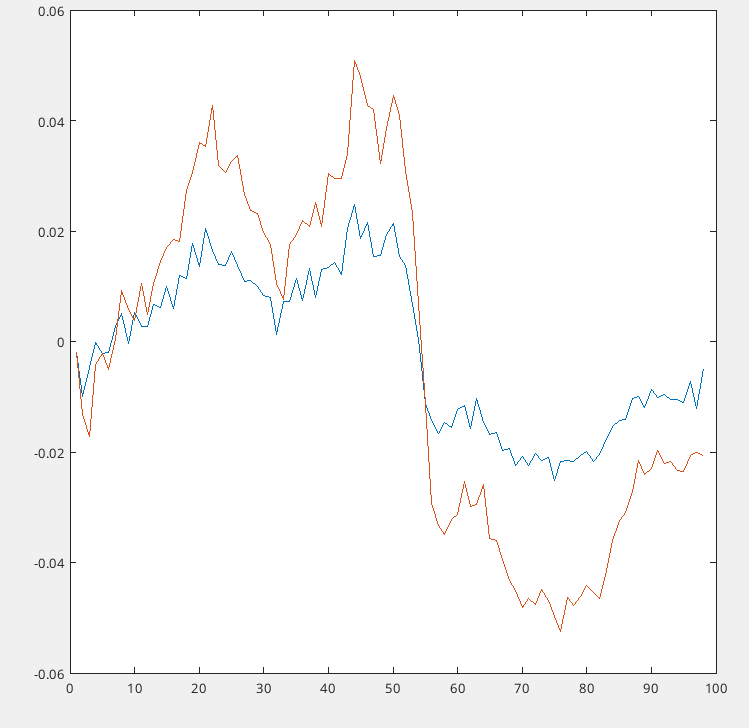
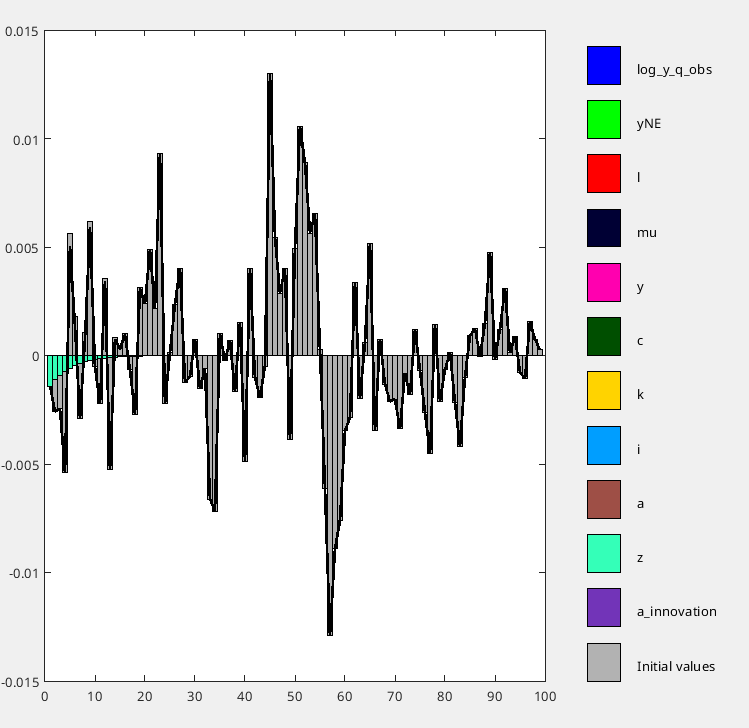
Model Specification: Following Canova (2014), I use log-level data with:
- A random walk with drift for labor-augmenting productivity
- Random walk “noise” components for measurement errors
- The productivity and noise drifts sum to match observed output growth
Key Observation: When I remove the unit root from the noise components (v0 version), the problem disappears - initial values decay monotonically for z. My understanding is that the Kalman smoother jointly determines initial states and shocks using the full sample. But why would this create non-monotonic initial value contributions for a simple AR(1) process? And why does the presence of unit roots in other (seemingly unrelated) parts of the model affect this? Any insights would be greatly appreciated!
rbc_v5_v1.mod (3.9 KB)
rbc_v5_v0.mod (3.7 KB)
data_example.csv (5.7 KB)