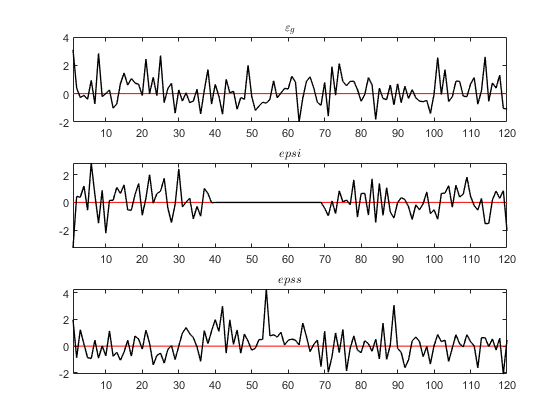
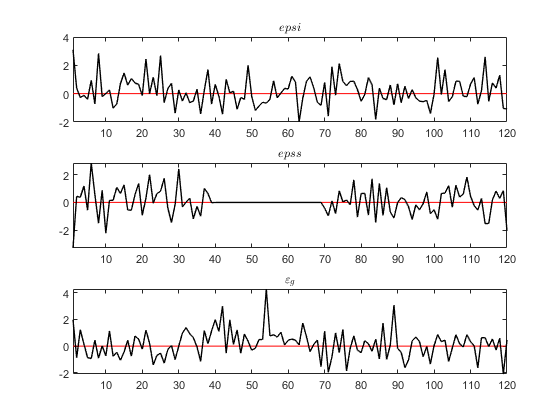
One issue I encounter is the way Occbin selects shocks that need to drop out during the periods when some observable is constant, say the interest rate when the ZLB binds.
In Johannes’ file, the command
inx = strmatch(‘epsi’,M_.exo_names);
if any(isnan(inom))
M_.heteroskedastic_shocks.Qscale_orig.periods=find(isnan(inom));
M_.heteroskedastic_shocks.Qscale_orig.exo_id=inx;
M_.heteroskedastic_shocks.Qscale_orig.scale=0;
instructs Dynare to drop the monetary shock when the interest rate drops out of observables.
When I run the file as it is written, and estimate the model using the inversion filter, I get the expected result: epsi is zero when the ZLB binds. See Fig 1 attached.
When I slightly modify the file to reorder the declaration of shocks, say to
varexo
epsi (long_name=‘Notional interest rate shock’)
epss (long_name=‘Risk premium shock’)
epsg {\varepsilon_g} (long_name=‘Productivity growth shock’)
;
the output I get signals that Dynare chooses to drop the risk shock instead of the monetary shock. This is in spite of the command instructing Dynare to drop the monetary shock. See Fig 2.
Even weirder, the smoothed shocks are the same as before, but the labels have changed - ie what Dynare calls epss, which now drops out during the ZLB, exactly corresponds to the smoothed epsi from the original version.
I ran into the issue by adding more shocks to the model and I would like to understand what is going on.
There is a one to one mapping between the declared observables varobs and the shocks varexo. In the example, inom is the second varobs, which has NaN values. Whenever that is the case, Dynare will drop the second declared shocks. By default, that was epsi. But in your second try, you moved epss to the second position, so that becomes the new shock to drop.
This makes sense. Thank you for the feedback Johannes.
I think it would be useful to clarify this link between the order of declaration of shocks and varobs in the Manual. It seems unlikely that people will choose the correct declaration order by chance. (Unless it is already written somewhere and I missed it.)
Also I wonder then about the role of the following command lines:
M_.heteroskedastic_shocks.Qscale_orig.periods=find(isnan(inom));
M_.heteroskedastic_shocks.Qscale_orig.exo_id=inx;
M_.heteroskedastic_shocks.Qscale_orig.scale=0;
Does Dynare actually use these in estimation if the shock-varobs mapping is defined only by the declaration order? Or does it only play a role for the piecewise Kalman filter estimation?
Dear @jpfeifer
while running the NKM.mod I encounter the following problem.
Error using NKM.driver (line 1004)
smoother redux does not recover full filtered variables results!
Error in dynare (line 308)
evalin(‘base’,[fname ‘.driver’]); I am running the model in Dynare 6.2. Should I run in another version of Dynare? Best,
@jpfeifer, sorry for any confusion. I have a question: Is the NKM_mh_mode_saved.mat file generated as a result of the mode-finding procedure in Dynare? I’m currently working on estimating a similar model using IF.
In that case, do I need to first run the code with some mode_compute option to find a mode and set cova_compute=1 to store the Hessian, and then use its results later with the mode_file option? I am trying to run the NKM.mod file without the NKM_mh_mode_saved.mat file first, but it is taking a very long time now
Yes, at the end, I want to conduct Bayesian estimation and get posterior means/mode of parameters, and I was also wondering how I can obtain the NKM_mh_mode_saved.mat file results first
You cannot get it “first”. It stands at the end of estimation. If someone else provides you with the file you can use. Otherwise, you have to first run the estimation chain to obtain it.
@jpfeifer Thank you for your response. I understand that I need to run the estimation chain to obtain it. However, when I run the code with MCMC by specifying the estimation command as:
// use inversion filter (note that IF provides smoother together with likelihood)
occbin_setup(likelihood_inversion_filter,smoother_inversion_filter);
estimation(datafile=dataobsfile2, mode_compute=6, cova_compute=1, nobs=120, first_obs=1, mh_replic=15000, plot_priors=0, smoother, consider_all_endogenous, heteroskedastic_filter, filter_step_ahead=[1:8], smoothed_state_uncertainty);
It does not produce results even after 4-5 hours. Is it normal for IF to take such a long time? And more importantly, am I specifying the command correctly? I would greatly appreciate your help.