Hello, I encountered a problem while using Dynare for estimation. I tried to search existing posts and materials but couldn’t find an answer.
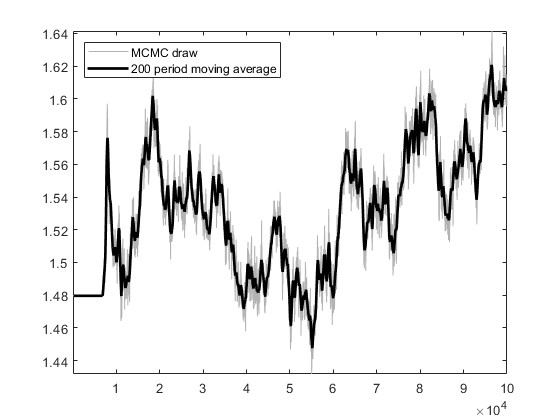
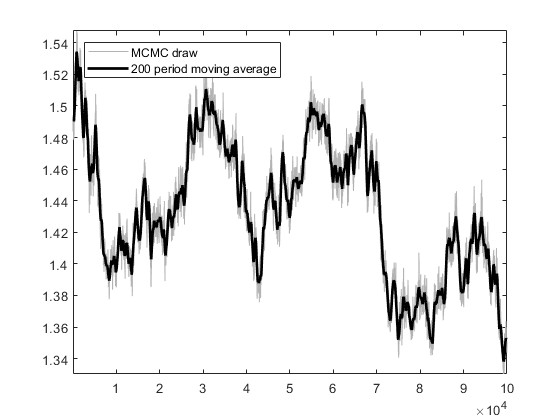
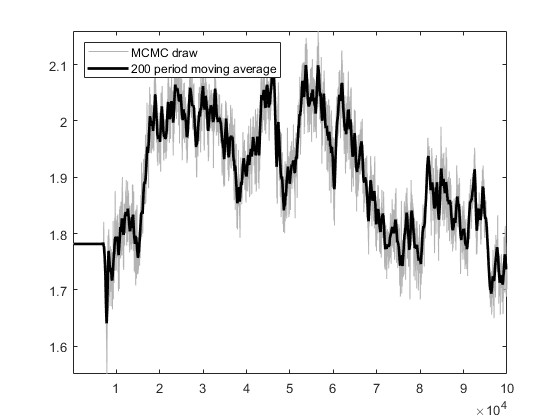
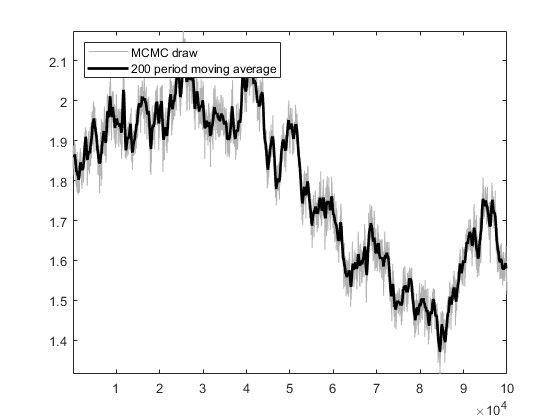
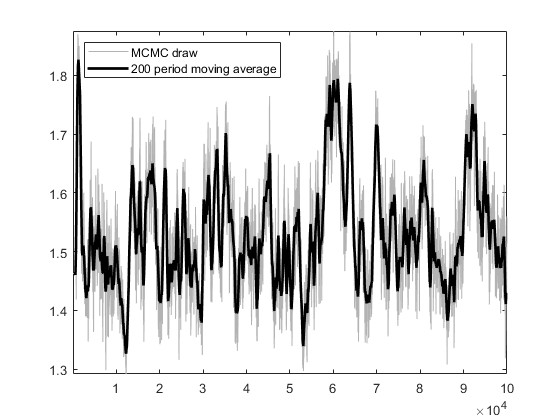
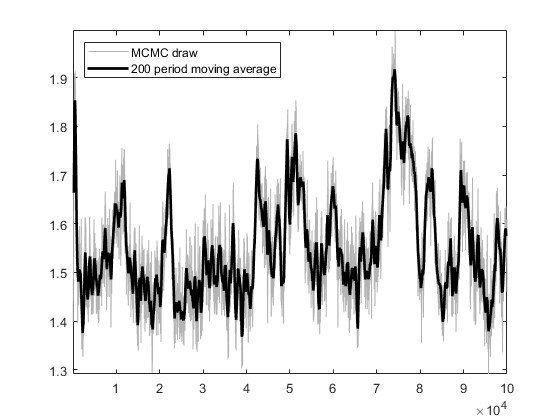
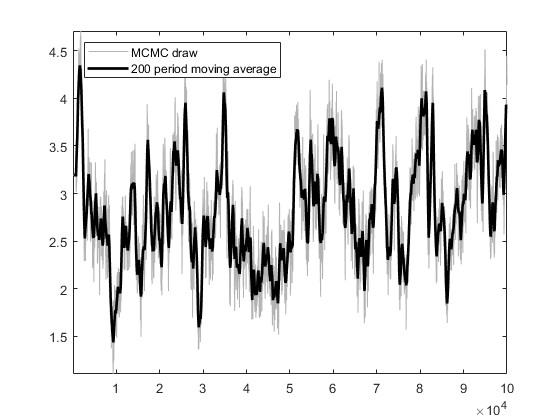
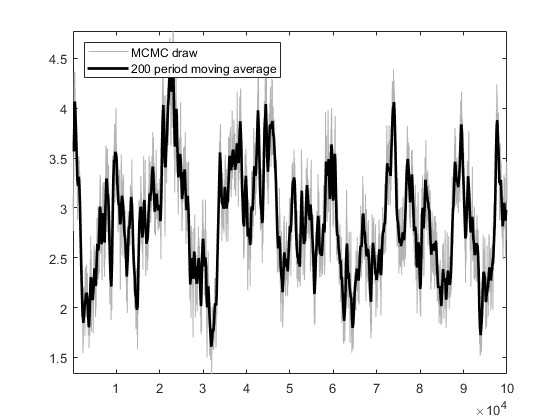
Based on the US_VI16 in MMB, I wrote a new model for estimation. The model has a total of 30 parameters to be estimated, and the prior, initial values, and bounds for the parameters are set using the settings in US_VI16. In SW2003, my data can pass MCMC convergence diagnostics and obtain estimation results.I attempted estimation with mh_replic=1000000 and found that the MCMC convergence diagnostics did not pass. I tried another approach: I first set mh_replic=100000, used the posterior means as new initial values, repeated this process three times, and found that the MCMC convergence diagnostics passed.
I would like to know if this approach is reasonable. Does it imply that, when the model derivation and data processing are correct, as long as the parameter settings are not too wrong, one can find an MCMC diagnostic convergence result through such an operation?
Since English is not my native language, I ask for your understanding if my choice of words or expressions may cause any discomfort. Sincerely, I appreciate every researcher willing to help me with my questions!
Hongming Zhang