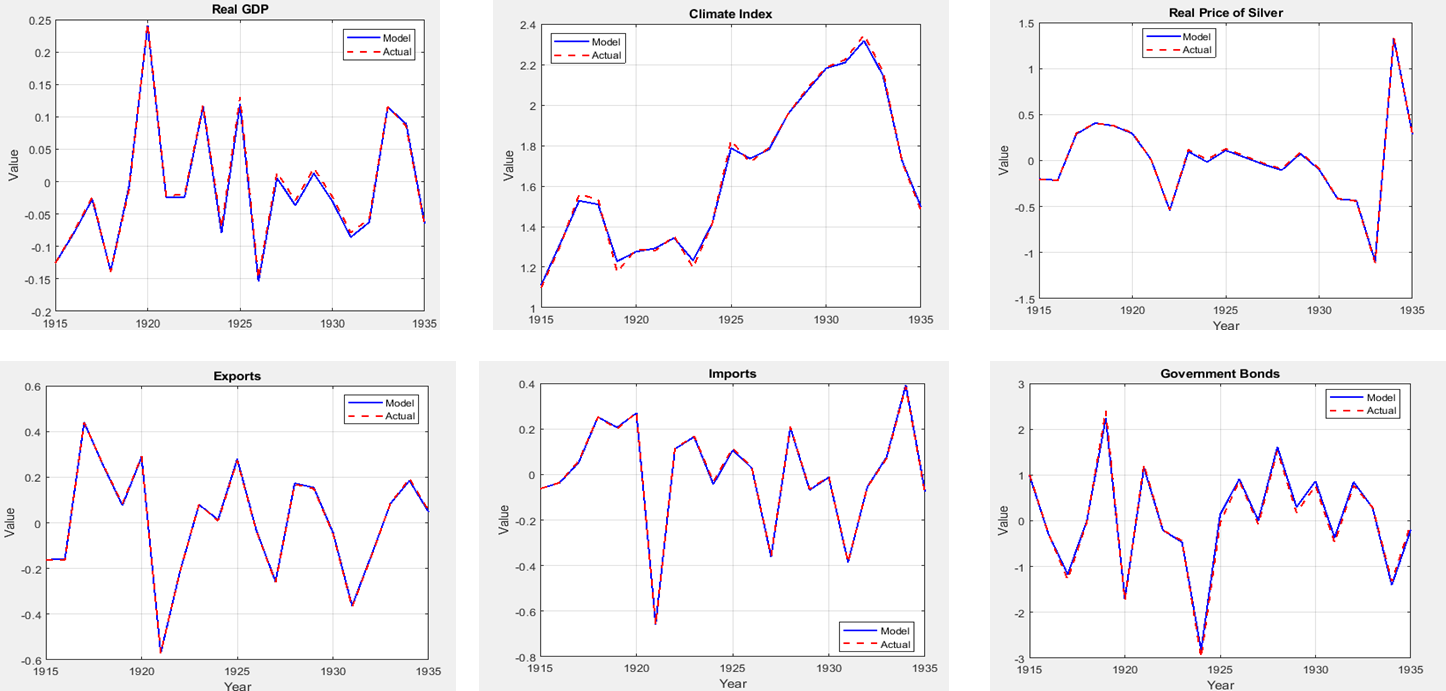
Hello everyone,
I’m facing a challenge with my DSGE model estimation in Dynare and would appreciate any insights from the community. My model works well with the stoch_simul command, but I encounter issues when using Bayesian estimation.
Currently, I can only successfully estimate the model with the following four observables:
y_us_obs, smdi_obs, real_price_silver_obs,real_exch_obs
However, my model has seven shocks, and I recall that, in theory, the number of observables should ideally match or exceed the number of shocks for full identification. This discrepancy raises concerns for me regarding the accuracy of the estimation results, as I’m working with fewer observables than shocks.
When I attempt to add more observables (such as pc_A_obs for agricultural value index, pc_N_obs for non-agricultural sector price index, y_obs for output, m_obs for money supply, im_obs for imports, and xp_obs for exports), I receive the following error message:
initial_estimation_checks:: The forecast error variance in the multivariate Kalman filter became singular.
initial_estimation_checks:: This is often a sign of stochastic singularity, but can also sometimes happen by chance
initial_estimation_checks:: for a particular combination of parameters and data realizations.
initial_estimation_checks:: If you think the latter is the case, you should try with different initial values for the estimated parameters.
ESTIMATION_CHECKS: There was an error in computing the likelihood for initial parameter values.
ESTIMATION_CHECKS: If this is not a problem with the setting of options (check the error message below),
ESTIMATION_CHECKS: you should try using the calibrated version of the model as starting values. To do
ESTIMATION_CHECKS: this, add an empty estimated_params_init-block with use_calibration option immediately before the estimation
ESTIMATION_CHECKS: command (and after the estimated_params-block so that it does not get overwritten).“
To preprocess my data, I use Stata to: 1. Log-transform and then difference each series; 2。 Detrend each differenced series to ensure a mean of zero.
My understanding is that the issue might be stochastic singularity due to potential collinearity among the observables. However, even if I add a single, seemingly independent variable, such as pc_A_obs (agricultural product price), which should not be collinear with variables like foreign output and exchange rate, I encounter the same error.
I also suspect that parameter dependence could be contributing to the issue. I read A Guide to Specifying Observation Equations for the Estimation of DSGE Models by Johannes Pfeifer, where parameter dependence is discussed, but I’m uncertain if this applies to my case. In particular, I’m concerned about the piz and bG variables. I attempted to define these with # to handle dependence, but this resulted in the following error:
piz has wrong type or was already used on the right-hand side.
Could anyone offer guidance on:
-
Whether having fewer observables than shocks in the current model setup could lead to unreliable estimates?
-
How to effectively identify and resolve any parameter dependence in piz, bG, or other variables, and whether this is indeed the root cause? The problem may arise from other issues??
-
Suggestions for handling the stochastic singularity problem, especially regarding the addition of more observables?
Thank you in advance for any advice you might have.
Best regards,
Yamoi
model_sim_bayesian.mod (26.2 KB)
data1911_19364.xlsx (7.3 KB)
param_and_ss_10_25.m (5.7 KB)