Dear all,
I am trying to create a ZLB environment in Dynare using a smooth penalty function rather than an occasional binding constraint. I start from a simple 3-equation NK model with a penalty function.
To do that, I impose a series of shocks which last from period 1 to 15, the total shock size is 1.
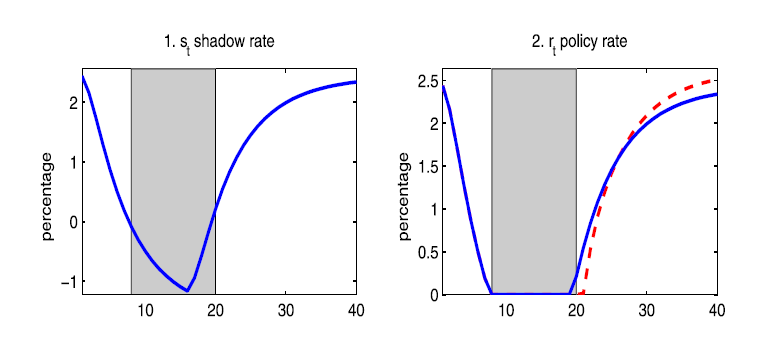
Ideally, I would love to have a figure like the one below (I found this figure in Wu and Zhang (2019)). On a certain period, the ZLB environment is created.
But using the code I uploaded, I only got a quite standard IRF result (below).
I initially expected the shadow rate, output, and inflation to continue declining for the first 15 periods, but they started to recover around period 5, which I find quite puzzling.
In Wu and Zhang (2019), the IRF graphs do not start at zero, and the policy rate only reaches the ZLB around period 8. However, in my IRF results, the policy rate reaches the ZLB right from the beginning.

I understand that occasionally binding constraints can impose a ZLB constraint, but for certain reasons, I have to use a smooth penalty function. If it were possible to achieve the desired results in Dynare while using a penalty function, that would be ideal.
Could my IRF results deviating from the expectated IRFs be due to incorrect code? Since I am dealing with a deterministic shock, I used perfect_foresight. Is this the reason why my variables tend to converge to zero earlier than expected? Or is Dynare not suitable for modelling a ZLB environment?
Could you please give me some suggestions on how to construct a ZLB environment similar to the one in Wu and Zhang (2019)? How can I impose a shock that ensures the ZLB occurs within a specific period range?
I would love to get an IRF graph in which a shock is imposed from period 1-15, policy rate and shadow rate start from around 2%. The policy rate reaches zero after around 10 periods and stays at ZLB for a while.
I would greatly appreciate any advice or assistance you can provide. Thank you very much! (attached with my code and Wu and Zhang (2019) if you are interested. They have shown a ZLB environment in their appendix ).
Thank you again for your time and patience.
Wu and Zhang (2019).pdf (1.5 MB)
try0.mod (2.2 KB)